Понятие shift-left на протяжении некоторого времени является популярной тенденцией в практиках непрерывного тестирования. Неожиданно, в последнее время мы начинаем видеть в тестировании новый тренд: «shift right».
Сдвиг вправо влечет за собой проведение дополнительного тестирования на этапах пререлизной и пострелизной версий (т.е. тестирование в продуктивной среде) жизненного цикла приложения. К ним относятся такие практики как: валидация релиза, деструктивное/хаос-тестирование, A/B и канареечное тестирование, CX-тестирование (например, корреляция поведения пользователя с тестовыми требованиями), публичное массовое тестирование, мониторинг сред эксплуатации, извлечение тестовых представлений и сценариев из данных продуктивных сред. Shift-right не только вводит такие методы тестирования, но также требует, чтобы тестировщики приобретали новые навыки, активно использовали данные продуктивных сред для разработки стратегий тестирования, сотрудничали с новыми заинтересованными сторонами такими, как SRE-инженеры и инженеры по эксплуатации. В тенденции к сдвигу вправо и расширении сотрудничества с эксплуатацией, мы видим эволюцию новой дисциплины в DevOps, которую называем TestOps.
Новые тенденции по смещению тестирования вправо
В недавнем опросе о непрерывном тестировании, проведенном Capgemini и Broadcom, тестирование на продуктивных средах было отмечено как наиболее широко применяемая практика (с 45% респондентов), либо уже внедренная, либо планируемая в настоящее время (см. Рисунок 1). Кроме того, 39% респондентов упомянули использование аналитики данных эксплуатации продуктивных сред для определения или оптимизации охвата тестированием. 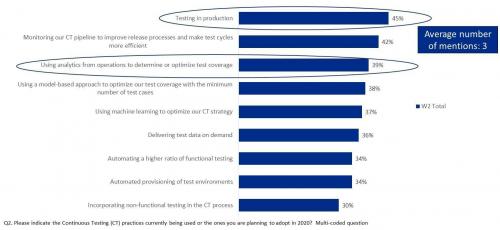
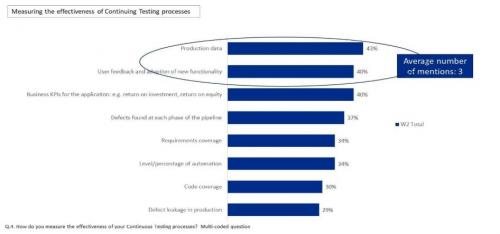
В ответах на вопрос о том, как клиенты измеряют эффективность процессов непрерывного тестирования, первое и второе место заняли производственные данные и отзывы пользователей, а также принятие пользователями нового функционала (см. Рисунок 2).
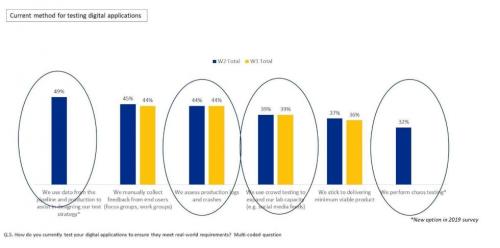
Наконец, на вопросы о том, как клиенты тестируют свои цифровые приложения, чтобы убедиться, что они соответствуют требованиям реального мира, почти все ответы были связаны с данными продуктивной эксплуатации (см. Рисунок 3).
Использование этих данных для разработки стратегии тестирования стало новой реальностью по сравнению с аналогичным опросом, проведенным год назад.
Данные опроса явно указывают на то, что клиенты активно практикуют (или рассматривают эту возможность) методы сдвига вправо для тестирования.
Что заставляет тестирование сдвигаться вправо?
Целью смещения вправо является обеспечение правильного поведения, производительности и доступности в процессе разработки, поставки и эксплуатации приложения. Есть несколько драйверов, которые заставляют сдвигаться в сторону эксплуатации.
Customer Experience (CX) — ключевой показатель качества для цифровых приложений
В отличие от классического тестирования, здесь учитываются реальные пользователи и их опыт. Приложение с идеальными показателями традиционного качества (например, FURPS) может по-прежнему страдать от плохого CX, если оно не может удивить и порадовать пользователя. CX измеряется с использованием различных показателей, таких как Customer Effort Score (CES), Net Promoter Score (NPS), Customer Satisfaction Score (CSAT), и т.д. Хотя некоторые из этих измерений можно сдвинуть влево в некоторой степени, большинство измерений CX могут быть получены только из продуктивных сред (или расположенных близко к ним). Примеры CX-тестирования включают в себя:
- Проверка требований на основе реальных операций пользователей, поведения и отзывов.
- Разработка и проектирование функциональных сценариев и тестов производительности на основе вышеуказанного.
- A/B-тестирование и канареечное тестирование, чтобы экспериментировать и проверять, насколько хорошо (или плохо) клиенты принимают изменения.
- Публичное массовое тестирование, чтобы лучше понять реальный пользовательский опыт.
В мире гибкой доставки может оказаться невозможным протестировать все перед выпуском в экcплуатацию
Время выхода на рынок (или время для внесения изменений) является главным бизнес-требованием для цифровых приложений, поэтому QA / тестирование считается основным узким местом в непрерывной доставке. Хотя можно оптимизировать усилия по тестированию и время цикла, используя практики сдвига влево (такие как тестирование на основе моделей, оценки влияния изменений, автоматизации тестирования), эти подходы могут все еще занимать слишком много времени (или требовать значительных усилий) в то время как команда пытается сократить время цикла выпусков продукта. В некоторых случаях истинные паттерны и способы эксплуатации могут даже не быть полностью поняты/осознаны до выпуска приложения на реальных пользователей. Идея состоит в том, чтобы изучить шаблоны использования (и работы) продуктивной среды и использовать их для улучшения стратегии тестирования в пределах сдвига влево.
Сложные и все более распределенные системы, использующие микросервисы (использующие тысячи компонентов), облачные технологии, которые позволяют выпускать новую/измененную функциональность с самыми малыми изменениями, усложняют полное тестирование приложений в отдельных средах тестирования. Это дополняется тем фактом, что, поскольку такие выпуски настолько гранулированы, их можно легко откатить назад в случае возникновения проблем.
Следовательно, компании тестируют, стремясь обеспечить «достаточно хорошее», а не «максимальное» качество (для обеспечения своевременного выпуска). Полагаются на быстрое восстановление (или откат) для устранения неизбежно возникающих дефектов или проблем.
Кроме того, измерения CX (как описано выше) часто обеспечивают реальную пользовательскую обратную связь во всем наборе оттенков, в отличие от черно-белого теста «пройдено / не пройдено» классического тестирования. Это дополнительно подтверждает то, что невозможно опираться только на усовершенствование тестовых наборов для подготовки к производству, чтобы обеспечить полное покрытие CX.
Стопроцентная надежность (или качество) часто является нереальной целью
В связи с вышеизложенным, один из ключевых принципов, которые мы изучаем из дисциплины DevOps SRE, заключается в том, что 100% надежность не только нереальна, но и слишком дорога. SRE определяет концепцию уровней обслуживания (SLO) и бюджетов ошибок для количественной оценки приемлемого допустимого уровня риска в продуктивных системах. Тот же принцип применим к тестированию и общему качеству.
Некоторые проверки сложно выполнить в тестовых средах
К таковым относятся крупномасштабные тесты производительности, когда тестовые среды не имеют размеров (мощностей и/или конфигураций), сравнимых с продуктивными средами.
Другой пример — деструктивное или хаос-тестирование. Хотя можно проводить изолированное хаос-тестирование в тестовых средах, используя такие методы, как виртуализация служб (для имитации сбоя в зависимых компонентах), его трудно выполнить для крупномасштабных деструктивных тестов. Например, Netflix проводит значительную часть своих испытаний на продуктивных средах.
Аналогично, корпоративный мониторинг для сбора информации о реальной эксплуатации, потреблении и о сбоях возможен только на продуктиве. Хотя мы выступаем за использование мониторинга в тестовых средах (как часть сдвига влево), такой мониторинг помогает только осуществлять локальные измерения (например, конкретного тестируемого приложения или системы). Тем не менее, сценарии тестирования производительности, разработанные тестировщиками, могут быть повторно использованы в продуктивных средах (двигаясь по оси и вправо и влево) в качестве синтетических метрик для измерения производительности, оценки регресса приложения.
Наконец, тестирование некоторых приложений с использованием ИИ может быть затруднено без доступа к данным продуктивных сред. Например, некоторые алгоритмы машинного обучения должны постоянно совершенствоваться на основе данных реального мира. Хотя эти алгоритмы разрабатываются с использованием ограниченного набора данных для обучения и тестирования, их необходимо адаптировать и дообучать на данных от реального использования продуктивных сред измеряемых приложений.
Разработчикам и тестировщикам нужна более простая и короткая связь с продуктивной эксплуатацией
Более короткая связь с продуктивной эксплуатацией в замкнутом контуре позволяет разработчикам и тестировщикам лучше понимать поведение приложения, прогнозировать успех / неудачу выпусков, реагировать на инциденты (например, сокращать MTTR).
Интерпретация и использование объемных данных часто трудны и утомительны для команд разработчиков и тестировщиков. Использование методов сдвига вправо позволяет разработчикам и тестировщикам более легко получать доступ к данным продуктивных сред в форме, которая легко потребляема и эффективна благодаря использованию правильных знаний из дисциплин AIOps. Такое использование данных является ключевым принципом парадигмы DevOps. Например, синтетические измерения/мониторинги, которые обычно создаются разработчиками и тестировщиками на этапах разработки / тестирования, предоставляют разработчикам средства для получения обратной связи по мониторингу в форме, с которой они знакомы.
Кроме того, автоматический анализ первопричин дефектов / инцидентов в продуктиве может дать разработчикам и тестировщикам понимание моделей и тенденций отказов, их источников, когда производственные данные соотносятся с данными разработки, причин которые их вызывают.
Аналогично, сценарии использования данных (например, из журналов базы данных, журналов транзакций) могут использоваться для генерации соответствующих тестовых данных.
В сущности, практика тестирования со смещением вправо необходима для создания непрерывного цикла обратной связи от реального взаимодействия пользователя с реальным приложением в сторону процесса разработки и тестирования.
Эволюция дисциплины TestOps
Из данных опроса клиентов и факторов, обсуждаемых выше, ясно, что существует эволюция в сторону сдвигающихся вправо практик.
Точно так же, как мы это делали со сдвигом тестированием влево, для того, чтобы сделать эти методы устойчивыми и реализовать заложенные в них преимущества, нам нужно также развивать варианты использования тестов, навыки, инструменты и шаблоны сотрудничества с людьми и дисциплинами правой области жизненного цикла приложения, т.е. эксплуатации. Другими словами, необходимо установить новую дисциплину TestOps, как субдисциплину в более широком контексте DevOps.
Хотя термин TestOps (как и все другие дисциплины x-Ops в DevOps) подразумевает сотрудничество между тестированием и эксплуатацией, речь идет не просто о сдвиге вправо. Почему? Потому что с DevOps эксплуатационные дисциплины сами сдвинулись влево (например, сдвиг влево в чати мониторинга, управления конфигурациями, SRE и т. д.). Следовательно, TestOps стремится к лучшему сотрудничеству с дисциплинами эксплуатации на протяжении жизненного цикла непрерывного тестирования в DevOps.
Давайте рассмотрим некоторые из ключевых практик в TestOps shift-left (см. Рисунок 4).
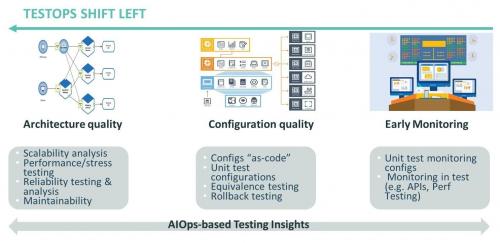
Раннее тестирование надежности: статический анализ масштабируемости архитектуры системы, а также тестирование производительности и стресс-тестирование.
Контроль качество конфигурации: тестирование среды «as-code» (все, что «as-code» может и должно быть протестировано как таковое, как и код приложения) и конфигурации развертывания, а также тестирование развертывания и тестирование отката.
Ранний мониторинг: мониторинг систем на ранних этапах жизненного цикла (например, в средах разработки и тестирования), а также разработка и тестирование синтетических метрик перед их развертыванием на продуктивных средах.
Раннее применение AIOps: раннее использование методов AIOps (в средах разработки и тестирования) для сбора результатов тестирования и анализа качества, например, для прогнозирования риска дефектов и выпусков.
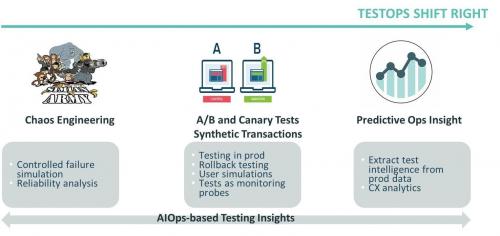
Ниже приведены некоторые из ключевых практик TestOps, посвященных смещению вправо (см. Рисунок 5).
Инженерия хаоса: проверка надежности системы путем внедрения сценариев контролируемого отказа.
A / B-тестирование: рандомизированный эксперимент с двумя (или более) вариантами изучения, которые более наилучшим обрабом принимаются пользователемя.
Канареечные релизы: методы, используемых для снижения риска внедрения новой версии программного обеспечения путем постепенного развертывания изменения на небольшой подгруппе пользователей, прежде чем распространять его на всю платформу / инфраструктуру и делать его доступным для всех.
Синтетический мониторинг: методы мониторинга с использованием эмуляции или записи транзакций по сценарию (которые отражают типичное поведение пользователя).
Тестирование и аналитика CX: извлечение данных CX, чтобы понять опыт клиентов, а также извлечь из них информацию (например, проблемы клиентов, требования к новым функциям и т. д.).
Прочие измерения продуктивных сред: тесты производительности и потребления, анализ данных тестирования приложений на основе AI.
Тестирование данных на основе данных AIOps: как описано выше, из данных операций можно почерпнуть множество различных идей для тестирования.
Ключевые навыки и инструменты TestOps
Давайте рассмотрим новые навыки, необходимые для ключевых практик TestOps.
- Навыки аналитики данных. Поскольку большая часть продуктивных данных является объемной, разнообразной и часто временной сущностью, тестировщики должны использовать аналитику данных, чтобы они могли быстро получить представление о этих данных, выполнить корреляции с другими наборами данных для принятия решений. Навыки расширенной аналитики (такие как предиктивная аналитика или машинное обучение) также необходимы для прогнозирования событий (например, предсказания качества релиза). Хотя эти навыки аналитики хорошо приняты в эксплуатационном сообществе (с ростом принятия AIOps), они относительно новы для разработчиков и тестировщиков.
- Навыки CX: Как мы уже говорили, CX теперь считается ключевым показателем для измерения качества приложения. Новые типы тестирования CX включают A / B и канареечные тесты, а также крауд-тестирование. Как и другие операционные данные, данные CX также обычно объемны и часто не структурированы. Тестировщикам необходимо приобрести достаточные навыки, чтобы получить представление о процессе и данных CX и эффективно сотрудничать с СХ-командами и специалистами.
- Навыки мониторинга и эксплуатации: Понимание принципов мониторинга (например, создание, тестирование и развертывание измерений, использование данных мониторинга) является ключевым навыком, необходимым для TestOps. Тестировщики также должны понимать принципы работы и эксплуатации приложения (инциденты, сбои, аварийные сигналы, MTBF, MMTR, определение конфигурации и т. Д.), Чтобы такая информация могла использоваться для целей тестирования, а также для совместной работы с эксплуатационными командами.
- Навыки надежности: надежность также является еще одним ключевым атрибутом качества работы, с которым должны быть знакомы тестировщики. Это включает тестирование на хаос / отказоустойчивость, тестирование развертывания и отката, а также тестирование конфигурации. Дисциплина SRE обеспечивает надежность, и многие ее принципы пересекаются с TestOps.
- Навыки работы с новыми инструментами. В дополнение к использованию традиционных инструментов тестирования, TestOps также требует использования дополнительных инструментов, таких как мониторинг, анализ данных (для производственных данных и данных CX), тестирование CX (такое как A / B и канареечное тестирование), тестирование надежности, применение машинного обучения.
Ключевые коллаборации TestOps практик
В дополнение к новым навыкам тестеры теперь должны научиться лучше сотрудничать с дополнительными заинтересованными сторонами. Это включает:
- Сотрудничество с наукой о данных и инженерами AI / ML. Это необходимо для тестировщиков для настройки или создания новых алгоритмов и моделей, необходимых для выполнения аналитики, необходимой для TestOps.
- Сотрудничество с инженерами и командами CX: это необходимо для мониторинга соответствующих метрик и данных CX, а также для изучения влияния их деятельности по тестированию / контролю качества на CX.
- Сотрудничество с инженерами и командами по операциям. Для TestOps важно не только поддерживать все операции тестирования, но и получать доступ к продуктивным данным, необходимым для аналитики TestOps. Это аналогично тому, как тестеры сотрудничают с разработчиками как часть shift-left.
- Сотрудничество с SRE: Как уже упоминалось, существует довольно много общего между принципами SRE и TestOps, и, следовательно, сотрудничество с SRE является ключевым для тестировщиков.
Автор Шамим Ахмед (Shamim Ahmed), оригинал публикации Shift-Right Testing: The Emergence of TestOps
Также по теме:
- Книга «RealITSM: проверено временем» поступила в продажу
- ВЖУХ, управление рисками и ITSM
- Почему только Agile уже недостаточно?
- Терпение, эволюция, политики и полномочия
- Как обстоят дела с ITSM





